



This post is a more technical review validating which algorithms perform best when analyzing A/B testing results. We felt this was an essential part of establishing a solid foundation for A/B testing analysis. We needed to feel confident we can make sound business decisions on the effectiveness of marketing programs that get tested in real life.
Why benchmark A/B testing algorithms?
It’s easy to understand why A/B tests get biased in real life: so many variables can change between the control group and the treated group. Selection bias is often hard at work and the two groups often end up being not really comparable without proper A/B testing analysis and a properly adjusted control group.
But how do you know your adjusted control group is right? How do you know it will give you a reliable estimate of the true impact of the program or campaign you are trying to evaluate? This is where benchmarking is really useful.
We start with synthetic data for which the true answer is known, and we run it through different libraries and different algorithms to see which ones give you a correct answer. The results are eye-opening, let’s get started!
Which A/B testing libraries did we benchmark?
After a preliminary evaluation of a range of open-source causal analysis libraries, our final list of contenders boiled down to two widely used libraries:
- CausalInference: Originally developed by Laurence Wong, causalinference is one of the oldest causal analysis libraries around. The library implements methods that are well documented in Imbens, G. & Rubin, D. (2015). Causal Inference in Statistics, Social, and Biomedical Sciences: An Introduction. It tends to be fast, and works well with most tabular datasets.
- DoWhy: Originally developed by a team of scientists at Microsoft Research, dowhy is one of the most robust causal analysis libraries. The library has become in many ways a standard and is now also endorsed by AWS data scientists. While it is one of the most robust libraries around, it also tends to be meaningfully slower than causalinference.
Other libraries we evaluated that did not make it to our final list include psmpy, causallib, causalimpact. We felt these libraries were either not mature enough or too narrowly specialized to be effective as our main analytical workhorse.
A/B testing benchmarking results
We used three synthetic datasets with different true impacts, so we could test what happens when the treatment effect is small, medium, or large. Results for the small effect case, which is most challenging, are graphed below. The chart shows the error of the estimate vs. the true treatment effect:
The results are pretty clear: propensity score matching works fairly well, with both causalinference and dowhy. In both cases the algorithm was able to estimate the treatment effect with near perfect accuracy, though dowhy was about 10x slower than causalinference.
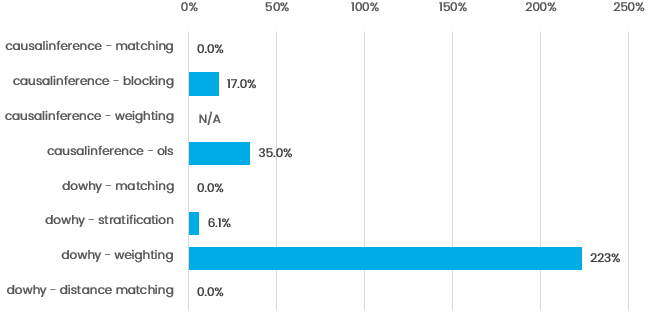
Propensity score weighting did worst across the board; dowhy generated a biased result but causalinference did not even produce a working result. Distance matching performed much better than we initially expected.
Full results are shown below for different effect sizes; the percentage is the error of the estimate vs. the true treatment effect :
| Library | Algorithm | Small effect | Medium effect | Large effect |
| causalinference | propensity score matching | 0.0% | 0.0% | 0.0% |
| causalinference | propensity score blocking | 17% | 3.4% | 0.3% |
| causalinference | propensity score weighting | N/A | N/A | N/A |
| causalinference | propensity score OLS | 35% | 7.0% | 0.7% |
| dowhy | propensity score matching | 0.0% | 0.0% | 0.0% |
| dowhy | propensity score stratification | 6.1% | 1.2% | 0.1% |
| dowhy | propensity score weighting | 223% | 45% | 4.5% |
| dowhy | distance weighting | 0.0% | 0.0% | 0.0% |
How Can We Help?
Feel free to check us out and start your free trial at https://app.g2m.ai or contact us below!
